Jobs & Templates

Jobs let you scale your Operations using self-service templates that let anyone run complex scripts with a custom GUI. You can control who can run jobs and which servers and environments jobs target.
Creating a Job Template
Jobs are created from job templates. You can create a job template by navigating to Jobs > Create Job Template. You can also navigate to the script you’d like to run and create a job template from that script.
When creating a job template, you need to specify:
- Script to run
- Server targeting
- Template variables
- User permissions
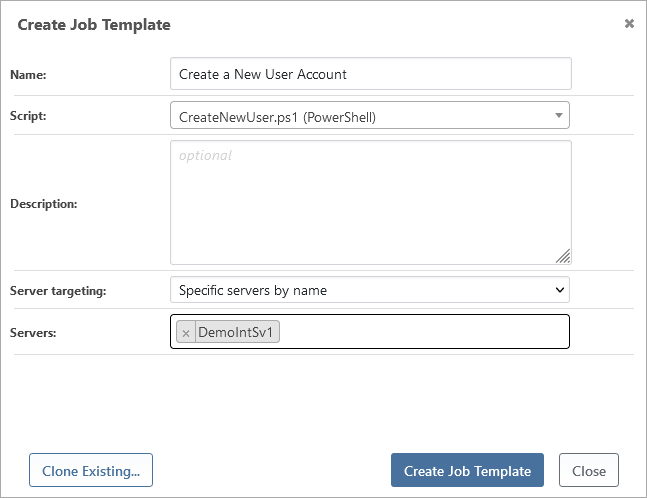
You can also clone an existing Job Template by clicking the "Clone Existing..." button in the lower left corner and selecting the Job Template you would like to clone.
Script to Run
The script to run can be OtterScript, PowerShell, or Shell scripts. See Scripts and Script Assets to learn how to manage these assets in Otter.
If you’d like to run a different script based on user input, you can create an OtterScript orchestration; see PowerShell and Shell Scripting to learn how.
Server Targeting
Scripts are run against a server, and there are three ways a job can target servers:
- Direct (simplest for just one or two): specify servers by name, and the script is then run against each server.
- Indirect (requires some planning ahead): specify a combination of roles and/or environments that will be used to specify the servers the script is run against.
- Custom (most complex but most flexible): perform complex orchestration that can run different commands or scripts on different servers. These servers can be targeted sequentially, in parallel, and with branching and iterating (looping) logic.
Note that, when using direct or indirect targeting, you can use variables names. See variables to learn more.
Overriding Server Targeting
By default, server targeting is restricted. This means that the user creating a job from a template cannot change the server targeting defined in the template.
You can make the server targeting editable at job creation time by configuring “Allow server targeting to be specified when creating a job.” Note that the user creating the job must have permission for the environments that the server is in; see the security and access controls to learn more
Template Variables (Prompts)
Before running a job, Otter can prompt the user for input using textboxes, checkboxes, and lists. The values entered in these prompts are used as parameters for the script before it is executed as a job.
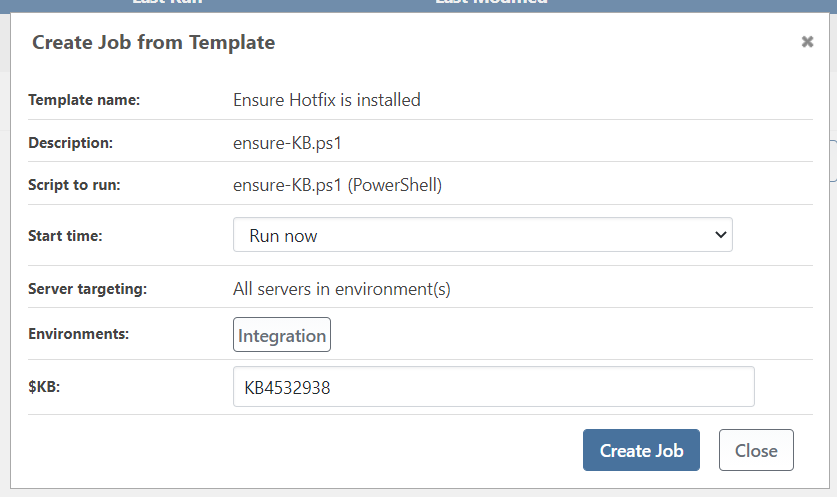
Name and Description
The name is added to the script as a runtime variable and needs to follow the normal variable-naming rules. The description is displayed to the user running the job as help text. The name is required, but the description is optional. Template variables can be required and have a default value.
Variable Types
A template variable can be text, a checkbox, or a list.
When you select a list type, you’ll need to enter the list values (one per line). You can select “Restrict value to items in list,” which will require the user to select one of the list values. You can also select “allow multiple items” in a List Template Variable. This will allow the user to select multiple values in the list, and the value will be added to the script as a list runtime variable.
Dynamic Lists
Template variables can also be a dynamic list. These use a data source for list items instead of manually entering values into the template. The built-in dynamic lists include environments, servers, universal packages, etc., but they are also extensible (you can create your own using the SDK).
Controlling Who Can Create Jobs
You can configure access controls (Admin > Tasks) to decide who can run jobs from templates. If you select “Allow creating jobs from user interface,” it will be accessible to users who have permissions who can run jobs from templates.
Creating a Job Using the API
Creating a job from the API first involves creating an API key with the “Job Orchestration” permission.
If you give the API key “Job Orchestration” permission, it can then be used to create and execute job templates from the API.
You can also restrict the job to a specific API key, which may be useful if you’re using different tools and scripts run different jobs in Otter.
When triggering jobs from the API, you may not wish to use template variables to add script parameters and to validate the proper parameters in the script itself. If you select “Allow new variables when creating a job,” you can pass in any number of variable name/values when running the job from the API.
Running a Script without Job Templates
You can also run a script directly without first creating a job template using an “Ad-hoc Job.” This can be a useful way to run scripts quickly and conveniently against a number of servers.
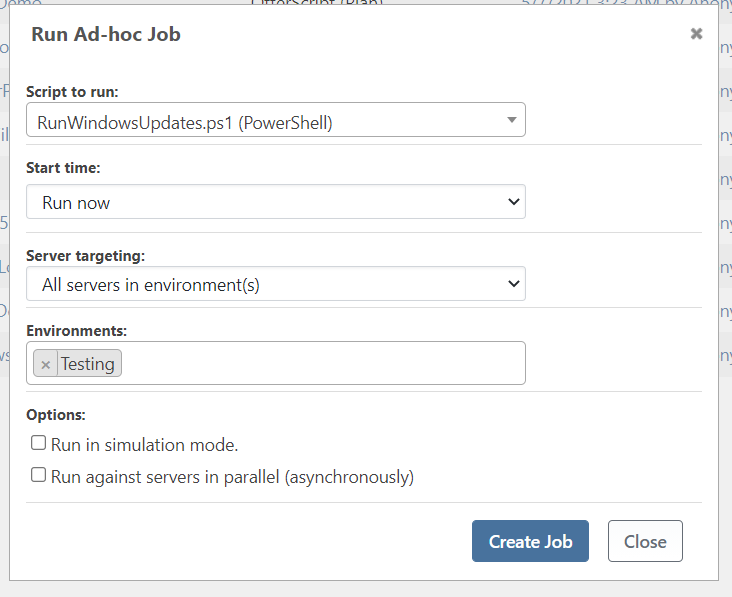
Note that this requires the “Create Without Template” permission.
Simulating Job Runs
Ad-hoc jobs can be run in simulation mode, which essentially runs the job execution logic without sending commands or running scripts to actual servers. Use simulation mode to test, for example, Custom-targeted jobs to see what servers the job would run on and to ensure that all/only the correct servers are used.
Troubleshooting Failed Jobs
Errors in the script, unavailable servers, network issues, etc. can cause jobs to fail.
To find failed jobs, go to “Job History.”
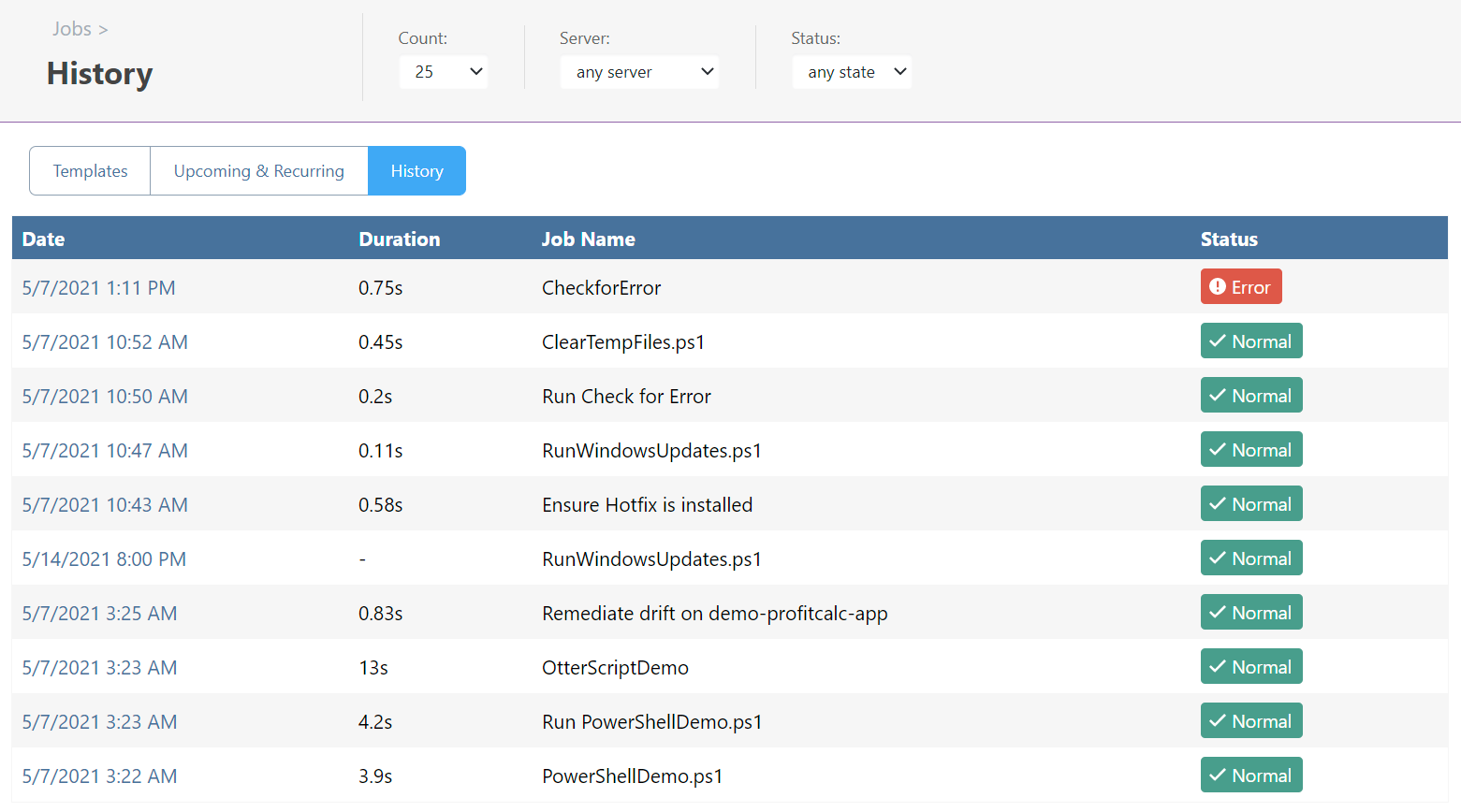
You can filter on failed status, then drill down to see exactly where the failure occurred. There’s also try/catch and retry that you can use with OtterScript.