What is a “Pipeline” in BuildMaster?

Pipelines let you build a repeatable release process by defining the servers and environments that your builds will be deployed to, as well as the manual and automatic approvals required at each stage of the process.

A basic web application might use a pipeline with only two stages (testing and production), and simply deploy to a different folder on the same server. Another application may require a dozen stages, each with multiple targets that go to different environments, and require all sorts of automatic and human approvals to meet compliance requirements.
Creating Pipelines
To create a pipeline, navigate to Settings > Pipelines in your application, then click Create Pipeline. You'll be able to create a pipeline from a template, copy an existing pipeline, or create a blank pipeline.
After you've created a pipeline, you can select it when creating builds and releases.
Pipeline Templates
To help model your existing build and deploy processes, BuildMaster includes some templates to help you get started.
- Git-based Templates
- Main/Release Branch; builds an application from a main or release branch, deploys it to an Integration stage, then a Test, and finally a Production stage.
- Hotfix Branch; builds an application from a hotfix branch, then provides options to deploy to Integration, Testing, or Production stages.
- Feature Branch; builds an application from a Git feature branch, deploys it to an Integration stage, and later creates a pull request and rejects the build to prevent further deployment.
- Develop Branch; builds from a development branch, deploys to an Integration environment, and later rejects the build to prevent further deployment.
- ProGet Package Pipeline; builds a pre-release package (such NuGet, PyPI, or npm), publishes it to a ProGet feed, and later Repackages/Promotes into a stable package.
- Import & Deploy Artifacts; imports artifacts from a CI server, and later deploys them to an Integration stage, then a Test, and finally a Production stage.
Name, Description & Color
A pipeline has three properties that help distinguish it: name, description, and a color. While the description is primarily used to guide users on which pipeline to use, the name and color are used to visualize the builds and releases that are utilizing that pipeline.
Enforcing Pipeline Stage Order
Generally, a pipeline is used to enforce a consistent release process, where builds are first deployed to an integration environment, then other testing environments, and then finally production. For some applications or scenarios—such as an emergency hotfix—this behavior may not be desired.
If you uncheck the "Enforce pipeline stage order for deployments" setting under Pipeline Details, your pipeline will allow users with appropriate permissions to deploy to any stage, at any time, without needing the Force permission. You can still Stage Requirements (Checks & Approval Gates).
Global Pipelines
You can also create a pipeline at the global-level, which means it can be used by all builds in all applications. Global pipelines behave in the same manner, with the exception that global pipelines may only reference global deployment plans.
Pipeline Stages
Pipelines contain a sequence of stages that builds will pass through on their way to production. For example, here are two stages (Testing and Production) of a pipeline:

Each stage defines Stage Requirements (the Checks & Approval Gates required for entry), the Deployment Targets (where and how build will be deployed), and whether the build will automatically or manually advance to the next stage.
Multiple Builds in the Same Stage
When a build enters the same stage as another build, the other older will be automatically rejected. For example, if Build #18 has been deployed to the Testing stage, deploying Build #19 to the Testing stage will automatically Reject Build #18. You can control this behavior by editing the stage's multiple active builds setting.
Stage Requirements (Checks & Approval Gates)
You can configure any number of Stage Requirements that must be met before a build can be deployed in that stage. For example, before being deployed to production, you may wish that:
- a tester signs-off on the build (Manual Approval)
- the code was built from the
release/*branch (Git Branch) - deployment occurs early Sunday morning, during off-hours (Deployment Window)
- ensure that no unstable (pre-release) or vulnerable packages were used (Packages/Dependencies)
The following is a list of all currently available stage requirements:
| Requirement Type | Notes |
|---|---|
| Manual Approval | Requires a user or member of a group to approve and enter a comment. |
| Deployment Window | Restricts to specific days of the weeks and times. |
| Git Branch | Ensures the build is using a specific branch or pattern. |
| Testing | Validates that tests recorded in the previous pipeline stage either all passed or none failed. |
| Issues Status | Prevents builds from being deployed to a particular stage unless all issues are closed. |
| Packages/Dependencies | Prevents builds from being deployed when there are open issues or unstable (pre-release) versions on Packages & Dependencies. |
| Required Variable Values | Ensures a specified variable value is set before promotion to the pipeline stage. |
| Custom Tool | Executes a custom tool via the command-line on the BuildMaster server and checks the exit code. |
| Files in Artifact | Verifies that a file exists in an Artifact before a promotion to the pipeline stage. |
| Other Pipeline Status | Ensures a pipeline stage of another application has been completed. |
Deployment Targets
When a build is deployed to a pipeline stage, BuildMaster will run the script you specify against a server target. For example, when you deploy to the Production stage, you can configure a script named Deploy to run against two servers (prodappsv1 and prodappsv2).
Script
You can specify any script that you've added to BuildMaster—OtterScript, PowerShell Script, Python Script, etc.—to run against servers you specify in a deployment target. This script can be global, in which case, it will start with global::.
Server Targets
There are four types of Server Targets:
- Specify servers by name, which will run the script to be run against each server in the list
- Specify a combination of roles and/or environments, which will look up the servers in the specified roles and/or environments, and then run the script against those servers
- Specify a server pool, where the next available server in a specified role will be used to run the script
- Custom (OtterScript only), which requires that you specify your servers in your OtterScript
You can use variables names like $TargetServer or $DeployToRole to specify the servers, roles, or environments you wish to use.
When you target multiple server roles, the script will be executed once for each role selected, against all servers with that role and in the target environment. This means that, if you target two roles—and one server happens to have both of those roles—the script will be executed against that server twice.
Custom Server Targeting
When you specify Custom as the Server target, you'll need to to specify the servers to use in your OtterScripts. You can do this with the for server or foreach server block, such as:
foreach server in @ServersInRole(my-prod-servers)
{
if ($ServerName == prodapp1)
{
Windows::Stop-Service MySpecialService;
}
Windows::Stop-Service MyServiceName;
«other-operations»
Windows::Start-Service MyServiceName;
}
This will allow you to perform complex orchestration that can run different commands or scripts on different servers. These servers can be targeted sequentially, in parallel, and with branching and iterating (looping) logic.
Under the hood, when you select a non-custom server targeting option, BuildMaster will wrap your script in OtterScript that uses a combination of statements like for server, foreach server, and Acquire-Server (for server pools).
Permission & Restrictions (Environment Targeting)
You can control which users are permitted to deploy to different stages by selecting "require environment-specific permissions to deploy" on the stage.
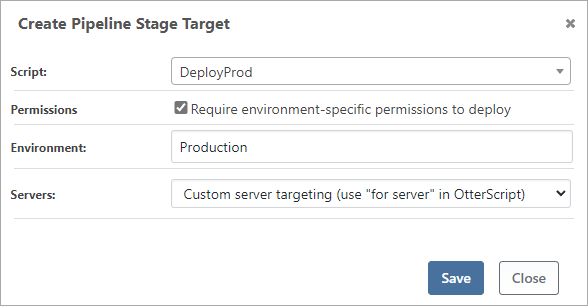
Checking this box has a few effects:
- Permissions: users must have permission to deploy to that environment in order to deploy to that stage
- Role Selection Filtering: if you also target by role, the server must be in that environment to be included
- Runtime Server Protection: a server must be in the target environment, or a runtime error will occur
- Visualization: this helps you see which builds have been deployed to which environments
Multiple Deployment Target Execution Mode
You can define multiple Deployment Targets per stage. When doing this, you can control how these will execute:
- Parallel - all deployment targets will run at the same time
- Sequentially - all deployment targets will run in the order specified
Automatically Promoting (Advancing) to the Next Stage
At the bottom of the pipeline stage, you can change whether or not a build will be automatically- or manually-promoted to the next stage after a successful deployment.

When a pipeline is configured to automatically promote, builds will automatically be deployed to the next stage upon a successful deployment, as soon as all requirements for following stage are met.
For example, if builds are configured to Automatically promote from Integration to Testing, but you've added a Manual Approval called Smoke Tests Passed, builds will be promoted to Testing only after someone checks that box.
Pipeline Events & Listeners
As a build progresses through a pipeline, various events such as Stage Deployment Successful or Build Rejected from Pipeline will be triggered. You can define Pipeline Event Listeners that will perform a certain action when these events occur.
For example:
- When Build Completes Pipeline → Tag Release in Git
- After Failed deploy to Production → Send Email
See Pipeline Event Listeners to learn more.
Pipeline Variables & Prompts
To help you reuse Scripts and create flexible Deployment Targets, you add variables to your pipeline and prompt users for their value at different parts of the process.
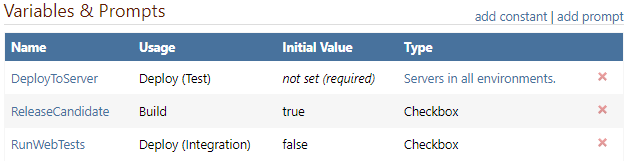
This can be useful, for example, if you want to allow users to select a server to deploy to.
See Variable Prompts (Templates) to learn more.